
목록) 오늘 배운 것
1. 행/열/인덱스 함수: 모양, 인덱스, 열, 값, dtypes
2. 데이터 검사: 헤드/테일, 샘플, 정보, 설명
3. 결측치 관련 기능 : 결측치 검색, 결측치 개수/비율
4. 행/열 인덱싱: 슬라이싱, loc
먼저 라이브러리를 가져오겠습니다.

강의 다음은 데이터 세트 예제입니다. mpg(마일리지)를 Seaborn으로 기록
df 변수에 저장했습니다.

pandas의 기본 기술 통계 기능을 살펴보겠습니다.
1. 행/열/인덱스 기능
(양식, 색인, 열, 값, D유형)
1-1 모양: 열과 행의 모양 찾기
>> (레코드 변수).Form
전)

– df.shape를 통해 389행/9열 데이터 세트 식별
1-2 index : 행 인덱스 값 표시
>> (레코드 변수).index
전)
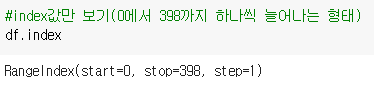
– 행이 0에서 389까지 1씩 증가하는 형태
1-3 열: 각 열의 제목 보기
>> (레코드 변수).열
전)
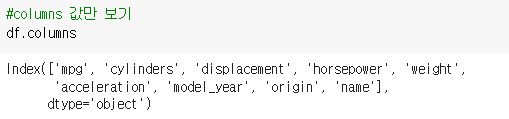
– 총 9개의 컬럼이 있으며 각 컬럼명은 리스트로 제공됩니다.
1-4 값: 각 행의 값에 대한 대략적인 보기를 가져옵니다.
>> (레코드 변수).values
전)

– 각 행의 대략적인 셀 값
1-5 dtypes: 각 열에 있는 변수의 데이터 유형(유형)
>> (데이터세트 변수).dtypes
전)

– 숫자변수: mpg ~ model_year
– 범주형 변수: 출신, 이름
2. 데이터 검토
(머리, 꼬리, 샘플, 정보, 설명)
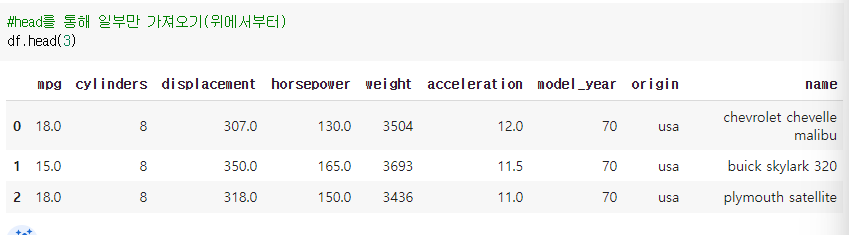
2-1 head: 상단에서 행 가져오기
>> (레코드 변수).head (조회할 행 수)
>> head()에 아무것도 입력하지 않은 경우: 위에서부터 5줄 조회
ex) df.head(3) : 위의 3줄 가져오기
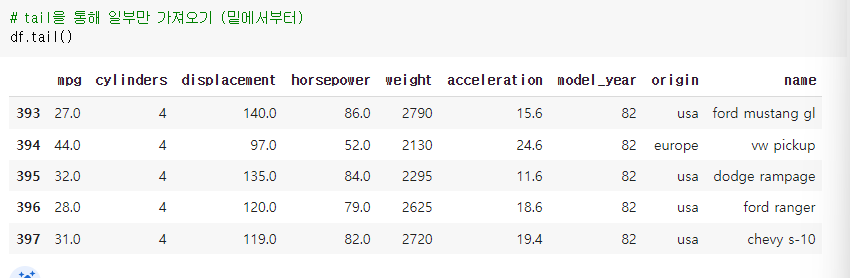
2-2 꼬리: 아래에서 행 가져오기
>> (레코드 변수).tail(조회할 행 수)
>> tail()에 아무것도 입력하지 않은 경우: 맨 아래에서 5줄 검색
예) df.tail() : 아래에서 5개 행 가져오기
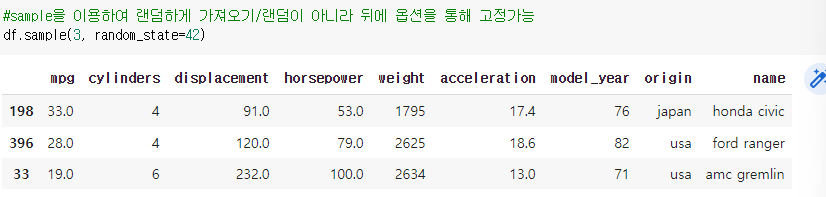
2-3 샘플: 무작위 추첨
>> (데이터셋 변수).sample(검색할 행 수, 옵션 모드)
>> 옵션 없이 사용할 때마다 임의의 데이터 행을 반환합니다.
>> random_stae=42 => 한 번 그린 데이터 세트 유지
예) df.sample(): 임의로 3행 검색
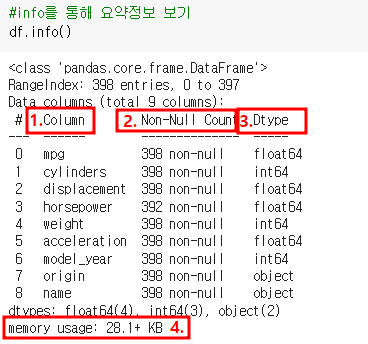
2-4 info: 각 열에 대한 대략적인 정보를 반환합니다.
>> (레코드 변수).info()
>> 1. 열: 열 이름
>> 2. non-null count: non-NULL 데이터의 개수
>> 3. dtypes: 데이터 유형(숫자)
>> 4. 저장소: 저장소 사용량
예) df.info(): 데이터셋의 요약 정보 표시
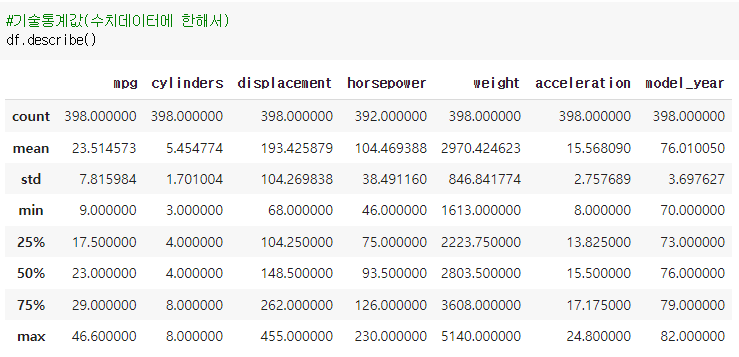
2-5 설명: 수치 데이터 기술 통계
>> (레코드 변수).describe()
(“describe”로 표시되는 기술통계)
1. 개수 : 행 수
2. 의미 : 의미
3. 표준: 표준편차
4. 최소/최대 : 최소-최대 값
5분위
예) df.describe(): 데이터셋 기술 통계(숫자 데이터에만 해당)
=> 범주형 데이터에 대한 설명 통계는 무엇입니까?
>> 설명(포함=”개체”)
(describe(include=”object”)에 의해 표시되는 기술 통계)
1. 개수 : 행 수
2. unique: 고유한 값의 수
위 3번째: 가장 일반적인 값
4. freq: 가장 빈번한 값의 빈도
예) df.describe(include=”object”): 데이터셋 기술 통계(카테고리 데이터)

3. 결측치 관련 함수
(결측치 검색, 결측치 개수, 결측치 비율)
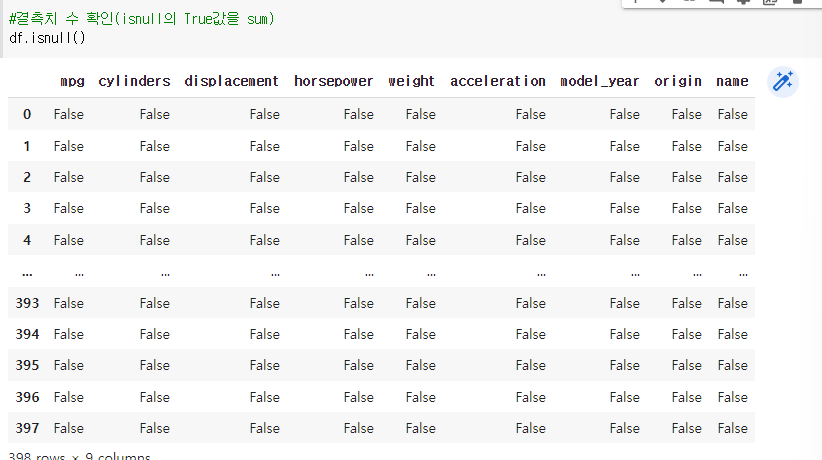
3-1 isnull/isna: 모든 셀이 없으면 TRUE를 반환하고 그렇지 않으면 FALSE를 반환합니다.
>> (레코드 변수).isnull()
>> (레코드 변수).isna()
예) df.isnull(): 누락된 값 검색
3-2 isnull/isna().sum() : 컬럼별 결측치 개수 확인
>> (레코드 변수).isnull(). 총()
>> (레코드 변수).isna(). 총()
예) df.isnull().sum() : 컬럼별 결측값 개수 확인
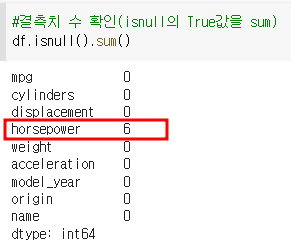
=> PS의 6개 값이 누락됨
3-3 isnull/isna().mean() : 컬럼별 누락된 값의 ‘백분율’ 확인
>> (레코드 변수).isnull(). 평균()
>> (레코드 변수).isna(). 평균()
>> 퍼센트 검색: (데이터셋 변수).isna(). 평균() *100
예) df.isnull().mean() * 100: 누락된 값에 대한 쿼리 비율

=> 마력에서 누락된 값의 1.5%
4. 행/열 인덱싱
(컷, 위치)
4-1) 시리즈가 있는 컬럼만 가져오기
>> 기록 변수. (‘열 이름’)
예) df(‘mpg’): df 데이터셋에서 mpg 열 가져오기

4-2) 데이터 프레임으로 가져오기
>> 기록 변수. ( (‘열명1’, ‘열명2’, ‘열명3’ ) )
=> 열 이름 목록을 입력하십시오.
예) df ( ( ‘origin’ , ‘name’ )): df 데이터 세트에서 origin 및 name 열 가져오기
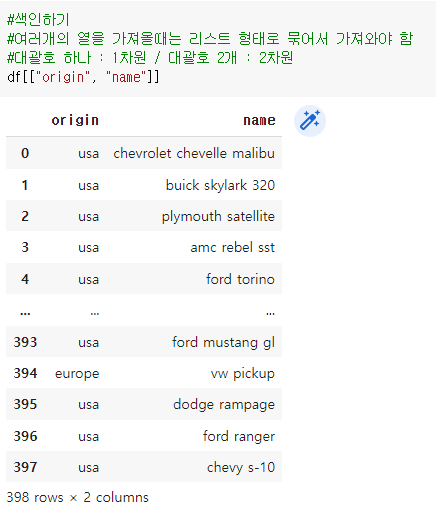
4-3) 위치
>> 행 가져오기: variable.loc 기록(행 번호)
>> 두 개 이상의 행 가져오기: Dataset variable.loc( (RowNumber1, RowNumber2..) )
>> 행 및 열 지정: Dataset variable.loc( (RowNumber1, RowNumber2…) , (ColumnName1, ColumnName2…))
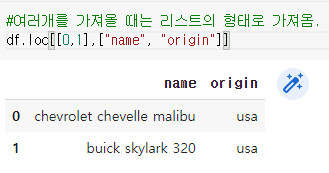
예) df ( (0 , 1 ) ( ‘원산지’ , ‘이름’ ) )
: df 데이터 세트/행 0 및 1에서 가져오기/원점 및 이름 열
참고 코스 주소) 네이버 부스트 코스 – 모두를 위한 데이터 사이언스
모두를 위한 데이터 사이언스
부스트 코스 무료 강의
www.boostcourse.org